计算机组成原理 - 程序的链接,装载和执行
本文打算从 ELF文件格式静态链接,程序装载,动态链接三个方面来分析一下,程序如何链接,装载和执行的。
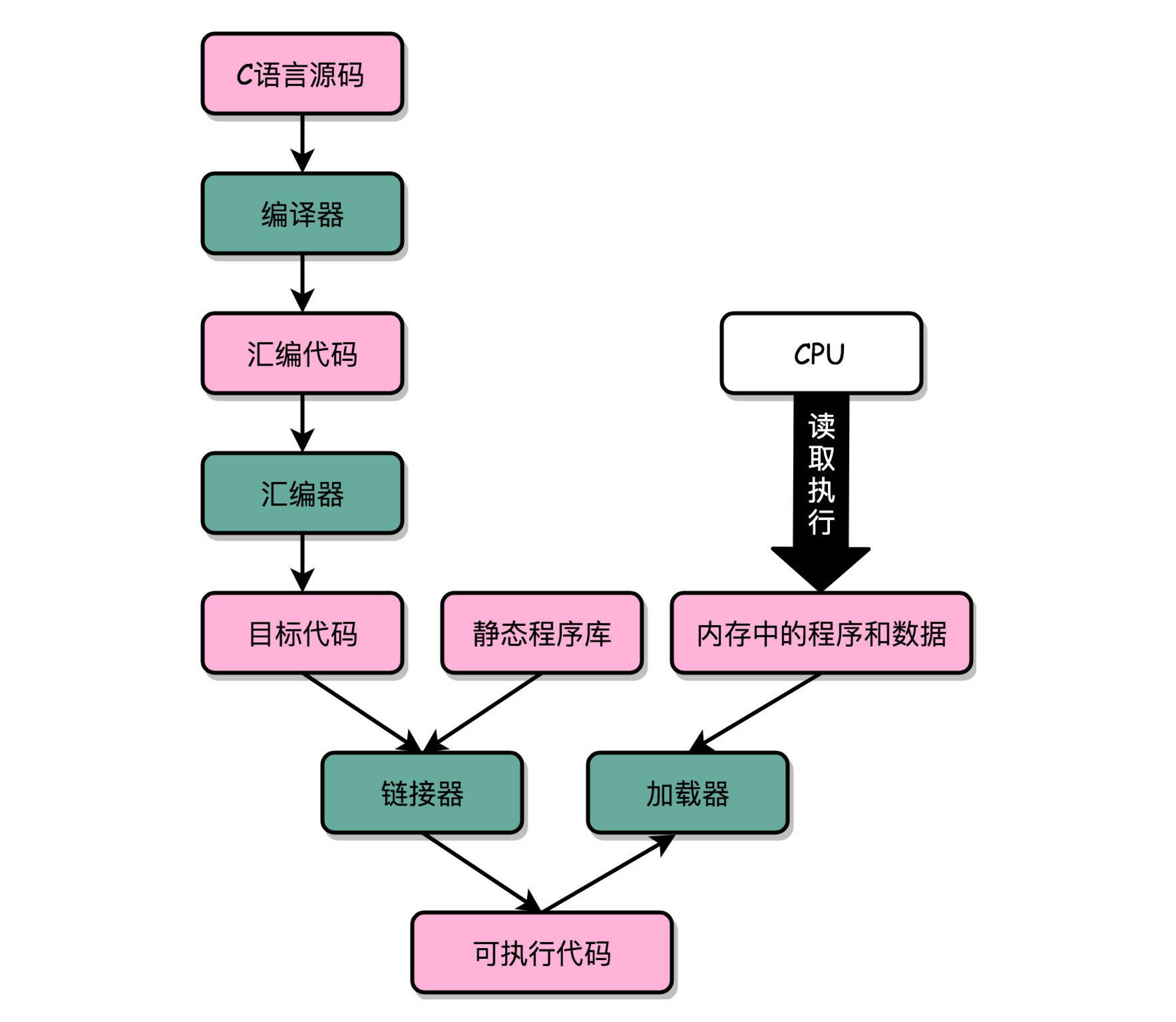
当程序比如 C 语言程序,编译成汇编代码,在通过汇编器编译成机器码后,会生成一个或多个目标文件,这时 CPU 还不能直接执行,需要通过链接器(Linker)把多个目标文件以及各种函数库链接起来,生成一个可执行文件。然后 CPU 在通过装载器(Loader)把可执行文件装载到内存中,进而从内存里读取执行和数据,来开始真正执行程序。
ELF 格式和静态链接
ELF(Execuatable and Linkable File Format)可执行和可链接文件格式。
简单来讲,正是因为 ELF 格式文件的存在,使得装载器无需考虑地址跳转等问题,直接解析该 ELF 格式文件,把对应指令和数据,加载到内存供 CPU 执行即可。
ELF 文件格式把各种信息,分成一个一个的 Section 保存起来,里面不仅有汇编指令,还有以下一些数据:
- 文件头: 表示文件基本属性。(是否可执行,CPU,操作系统是啥等)。
- .text Section: 代码段或者指令段,用来保存程序的代码和指令。
- .data Section: 数据段(Data Section),用来保存程序里面设置好的初始化数据信息。
- .rel.text Secion: 重定位表(Relocation Table),保留的是当前的文件里,哪些跳转地址其实是我们不知道的。
- .symtab Section: 符号表(Symbol Table),保留当前文件里面定义的函数名称和对应地址的地址簿。
那么 ELF 格式文件具体如何生成的呢?
- 首先链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。
- 然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。
- 最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。
这也是为什么,可执行文件里面的函数调用的地址都是正确的。
程序装载(内存分配优化)
装载器加载指令到内存,CPU 逐条执行。这里涉及到内存的分配,至少要满足以下两点:
可执行程序加载后占用的内存空间应该是连续的
我们需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。
很容易想到可以做一个映射关系,在内存里找一段连续的内存空间,分配给装载的程序,然后把这段连续的内存空间地址,和整个程序指令的物理地址做一个映射。
实际上就是虚拟内存地址和物理内存地址的映射关系。我们只需要关心虚拟内存地址,程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。
这种虚拟内存和物理内存映射的方法也称为分段,他有个不足之处,即内存碎片。
内存碎片导致即使有内存,但因不连续而无法充分利用,即程序装载不进来。当然可以解决,即采用 内存交换。先将最后几个程序写入硬盘,然后加载当前程序,最后再将写入硬盘的程序读到内存。Linux swap 硬盘分区,就是专门给 Linux 操作系统进行内存交换用的。
虚拟内存、分段,再加上内存交换,已经解决了计算机同时装载运行很多个程序的问题,这三者的组合仍然会遇到一个性能瓶颈。硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。
为了解决这个问题,采用了内存分页技术。和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。在 Linux 下,每一页我们通常只设置成 4KB。
当内存空间不够,我们需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,这样一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,更不会让整个机器被内存交换的过程给卡住。
当返回其它程序,操作系统发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault),操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。
这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
动态链接
程序装载到内存,根本的问题都是围绕内存不够用,如果我们能够让同样功能的代码,在不同的程序里面,共享一份内存空间呢,不就能节省内存了吗。
这个思路就引入一种新的链接方法,叫作动态链接(Dynamic Link)。相应的,我们之前说的合并代码段的方法,就是静态链接(Static Link)。
在动态链接的过程中,我们想要“链接”的,不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库(Shared Libraries)。
不过,要想要在程序运行的时候共享代码,也有一定的要求,就是这些机器码必须是“地址无关”的。换句话说就是,这段代码,无论加载在哪个内存地址,都能够正常执行。
对于所有动态链接共享库的程序来讲,虽然我们的共享库用的都是同一段物理内存地址,但是在不同的应用程序里,它所在的虚拟内存地址是不同的。我们没办法、也不应该要求动态链接同一个共享库的不同程序,必须把这个共享库所使用的虚拟内存地址变成一致。
那么问题来了,我们要怎么样才能做到,动态共享库编译出来的代码指令,都是地址无关码呢?
我们只需要使用相对地址就好了。各种指令中使用到的内存地址,给出的不是一个绝对的地址空间,而是一个相对于当前指令偏移量的内存地址。因为整个共享库是放在一段连续的虚拟内存地址中的,无论装载到哪一段地址,不同指令之间的相对地址都是不变的。
实际上,在进行 Linux 下的程序开发的时候,我们一直会用到各种各样的动态链接库。C 语言的标准库就在 1MB 以上。我们撰写任何一个程序可能都需要用到这个库,常见的 Linux 服务器里,/usr/bin 下面就有上千个可执行文件。通过动态链接这个方式,可以说彻底解决了这个问题。
总结
程序经过静态链接,程序装载之后,再通过动态链接把内存利用到了极致。这样,我们不仅能够做到代码在开发阶段的复用,也能做到代码在运行阶段的复用。
Title: 计算机组成原理 - 程序的链接,装载和执行
Author: Jiandong
Date: 2020-10-18
Last Update: 2025-02-23
Blog Link: https://mjd507.github.io/2020/10/18/Computer-Organization-4/
Copyright Declaration: Please refer carefully, most of the content I have not fully mastered.