计算机组成原理 - 高速缓存
来看 3 行代码,比较一下两个循环运行所花的时间。
1 | int[] arr = new int[64 * 1024 * 1024]; |
按道理来说,循环1 花费的时间应该是循环2 的 16 倍左右。但实际上,循环1 在我的电脑上运行需要 50 毫秒,循环2 只需要 46 毫秒。相差在 15% 之内,1 倍都没有。
这就是 CPU Cache (高速缓存)带来的效果。
程序执行时,CPU 将对应的数据从内存中读取出来,加载到 CPU Cache 里。这里注意,CPU 是一小块一小块来读取数据的,而不是按照单个数组元素来读取数据的。
这一小块一小块的数据,在 CPU Cache 里面,我们把它叫作 Cache Line(缓存块)。
日常用的 Intel 服务器或者 PC 中,Cache Line 的大小通常是 64 字节。
上面的循环2 里面,每隔 16 个整型数计算一次,16 个整型数正好是 64 个字节。所以,循环1 和循环2,都需要把同样数量的 Cache Line 数据从内存中读取到 CPU Cache 中,导致两个程序花费的时间就差别不大了。
CPU Cache 一般有三层,L1/L2 单核私有,L3 多核共享缓存(这里的 L1-L3 指特定的由 SRAM 组成的物理芯片,不是概念上的缓存)。有了 CPU Cache,内存中的指令、数据,会被加载到 L1-L3 Cache 中,95% 的情况下,CPU 都只需要访问 L1-L3 Cache,而无需访问内存。
Cpu Cache 读取数据
现代 CPU 进行数据读取的时候,无论数据是否已经存储在 Cache 中,CPU 始终会首先访问 Cache。只有当 CPU 在 Cache 中找不到数据的时候,才会去访问内存,并将读取到的数据写入 Cache 之中。
那么,Cache 如何根据内存地址定位到数据呢?
- 根据内存地址的低位,计算在 Cache 中的索引;
- 判断有效位,确认 Cache 中的数据是有效的;
- 对比内存地址的高位,和 Cache 中的组标记,确认 Cache 中的数据就是我们要访问的内存数据,从 Cache Line 中读取到对应的数据块(Data Block);
- 根据内存地址的Offset位,从Data Block中,读取希望读取到的字
如果在2、3这两个步骤中,CPU 发现,Cache 中的数据并不是要访问的内存地址的数据,那 CPU 就会访问内存,并把对应的 Block Data 更新到 Cache Line 中,同时更新对应的有效位和组标记的数据。
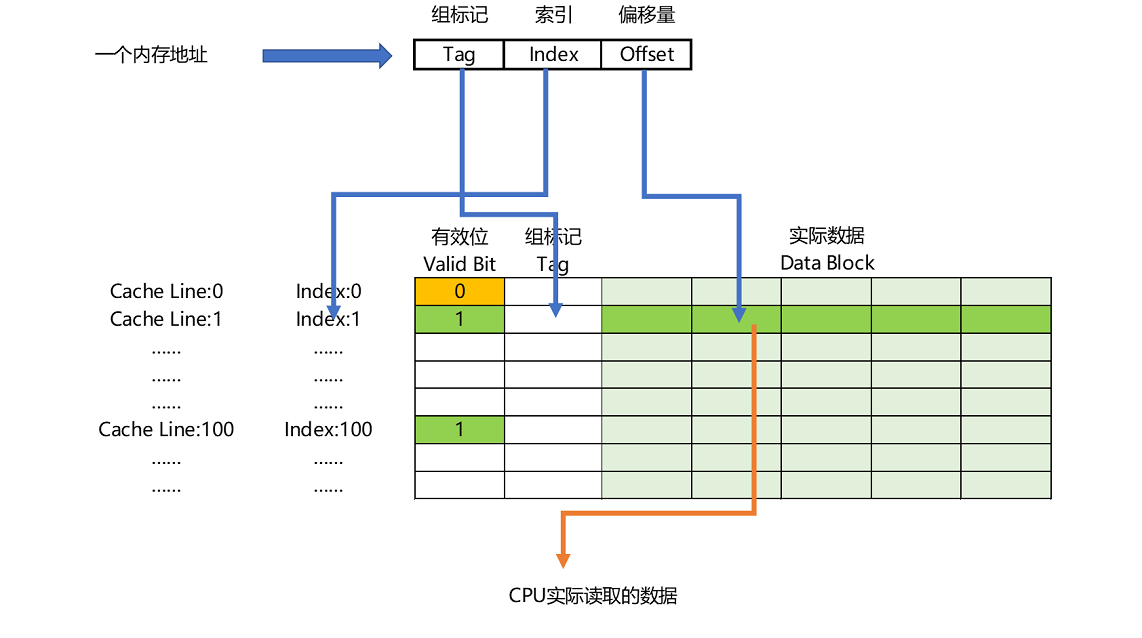
总结一下,一个内存的访问地址,最终包括高位代表的组标记、低位代表的索引,以及在对应的Data Block中定位对应字的位置偏移量。
Cpu Cache 写入数据
当 Cpu 要写入数据时,到底是写 Cache 还是写主存呢,如何保证一致性呢?
这里介绍两种写入策略。
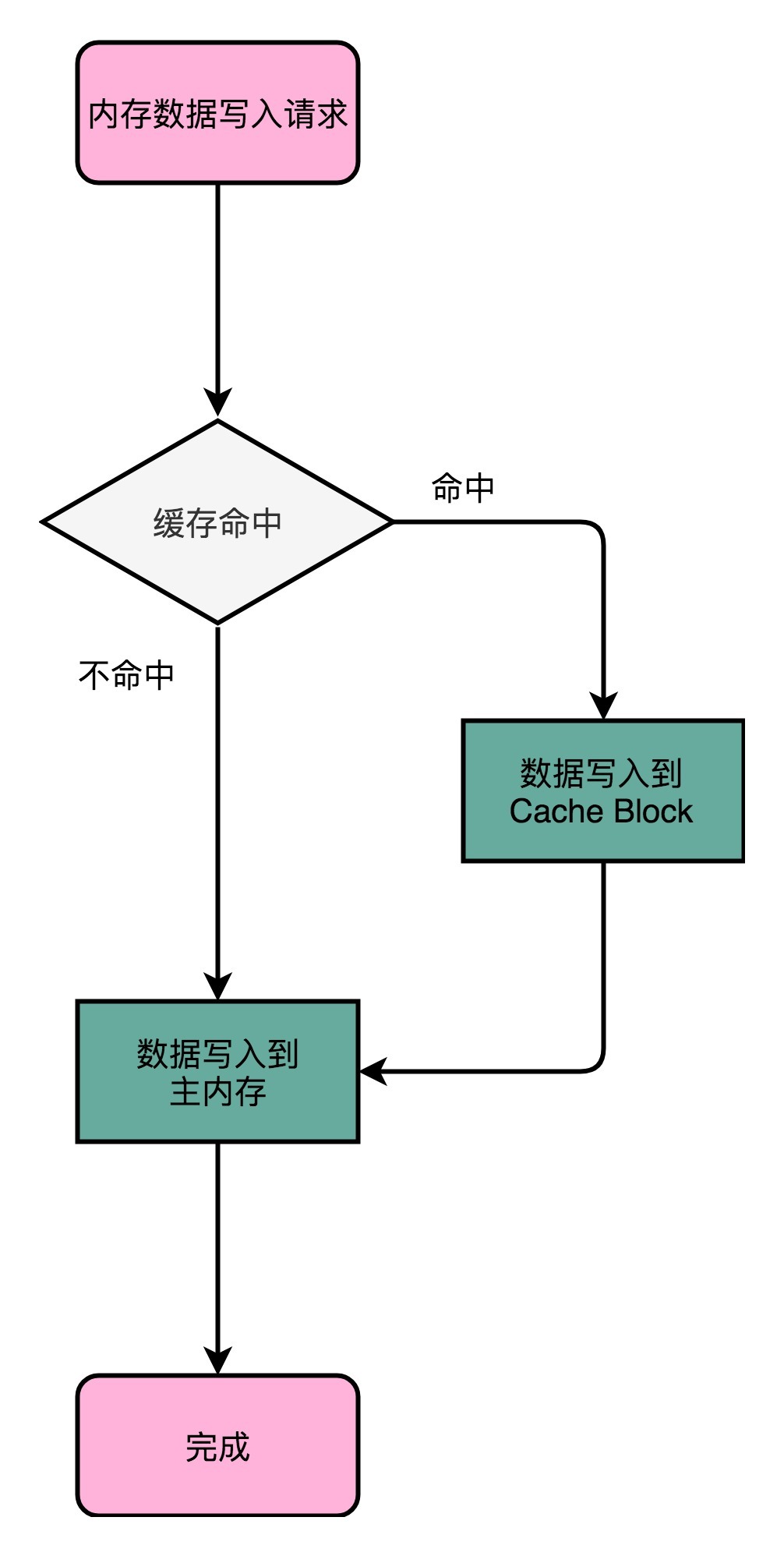
1. 写直达(Write-Through)
写入前,我们会先去判断数据是否已经在 Cache 里面了。如果数据已经在 Cache 里面了,我们先把数据写入更新到 Cache 里面,再写入到主内存里面;如果数据不在 Cache 里,我们就只更新主内存。
这个策略很直观,但是问题也很明显,那就是这个策略很慢。无论数据是不是在 Cache 里面,我们都需要把数据写到主内存里面。这个方式就有点儿像 Java 里 volatile 关键字,始终都要把数据同步到主内存里面。
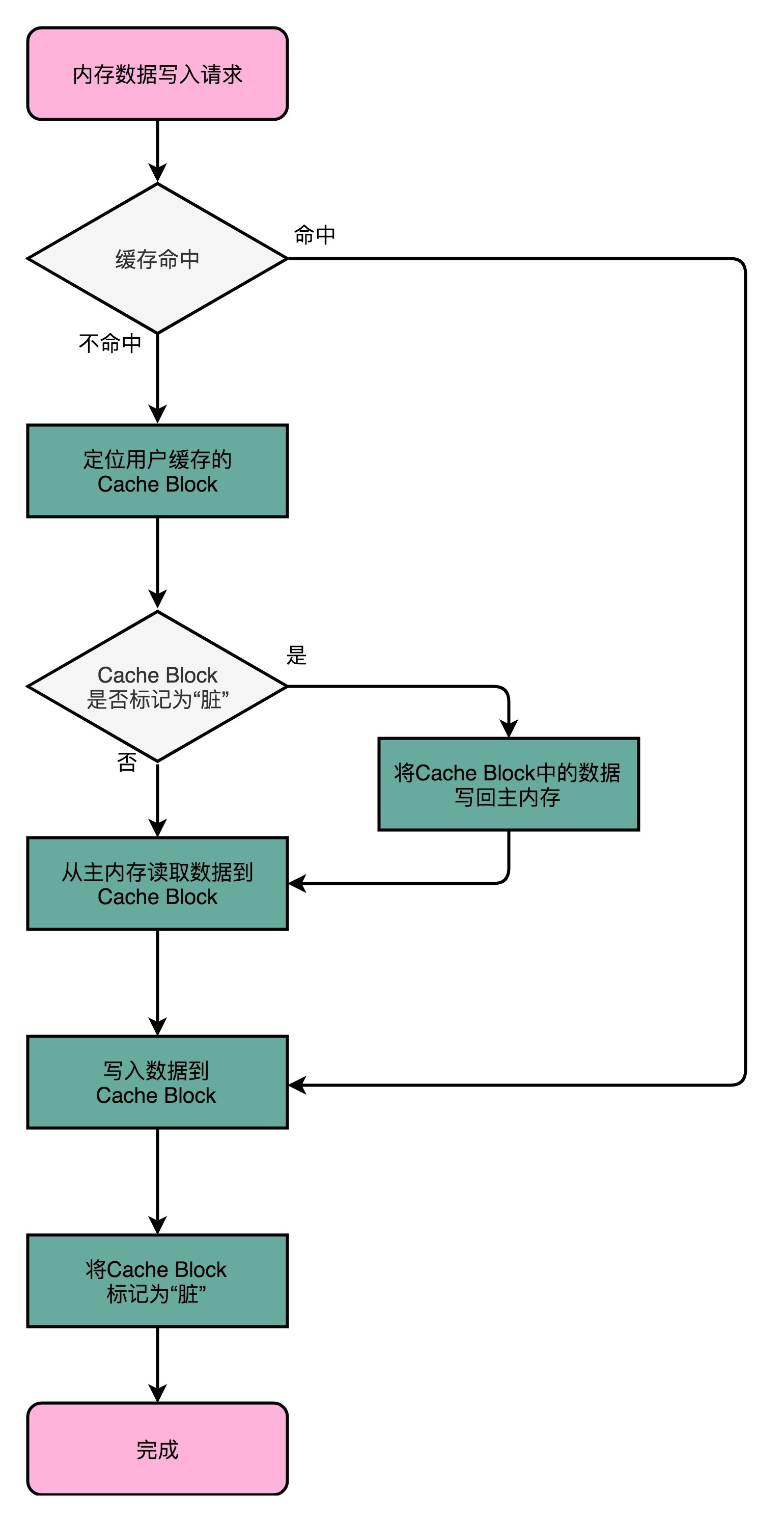
2. 写回(Write-Back)
如果要写入的数据,就在 CPU Cache 里面,那么就只更新 CPU Cache 里面的数据。同时标记 CPU Cache 里的这个 Block 是脏(Dirty)的。就是这个时候,CPU Cache 里的这个 Block 的数据,和主内存是不一致的。
如果要写入的数据所对应的 Cache Block 里,放的是别的内存地址的数据,那么就要看一看,Cache Block 里的数据有没有被标记成脏的。如果是脏的,要先把这个 Cache Block 里面的数据,写入到主内存里面。然后,再把当前要写入的数据,写入到 Cache 里,同时把 Cache Block 标记成脏的。如果 Block 里面的数据没有被标记成脏的,那么我们直接把数据写入到 Cache 里面,然后再把 Cache Block 标记成脏的就好了。
然而,无论是写回还是写直达,都没有解决多线程,或者是多个 CPU 核的缓存一致性的问题。
这也就是我们在写入修改缓存后,需要解决的第二个问题。
要解决这个问题,我们需要引入一个新的方法,叫作 MESI 协议。这是一个维护缓存一致性协议。这个协议不仅可以用在 CPU Cache 之间,也可以广泛用于各种需要使用缓存,同时缓存之间需要同步的场景下。
多核 CPU Cache 缓存一致性
因为多核 CPU Cache 在 L3 缓存是共享的,所以一致性问题,只会出现在 L1/L2 级这种单核私有缓存的场景中。
我们需要有一种机制,来同步两个不同核心里面的缓存数据。这样的机制需要满足两点:
第一点叫写传播(Write Propagation)。写传播是说,在一个CPU核心里,我们的Cache数据更新,必须能够传播到其他的对应节点的Cache Line里。
第二点叫事务的串行化(Transaction Serialization),事务串行化是说,我们在一个CPU核心里面的读取和写入,在其他的节点看起来,顺序是一样的。
CPU Cache 里做到事务串行化,需要做到两点,第一点是一个 CPU 核心对于数据的操作,需要同步通信给到其他 CPU 核心。第二点是,如果两个 CPU 核心里有同一个数据的 Cache,那么对于这个 Cache 数据的更新,需要有一个“锁”的概念。只有拿到了对应 Cache Block 的“锁”之后,才能进行对应的数据更新。接下来,我们就看看实现了这两个机制的 MESI 协议。
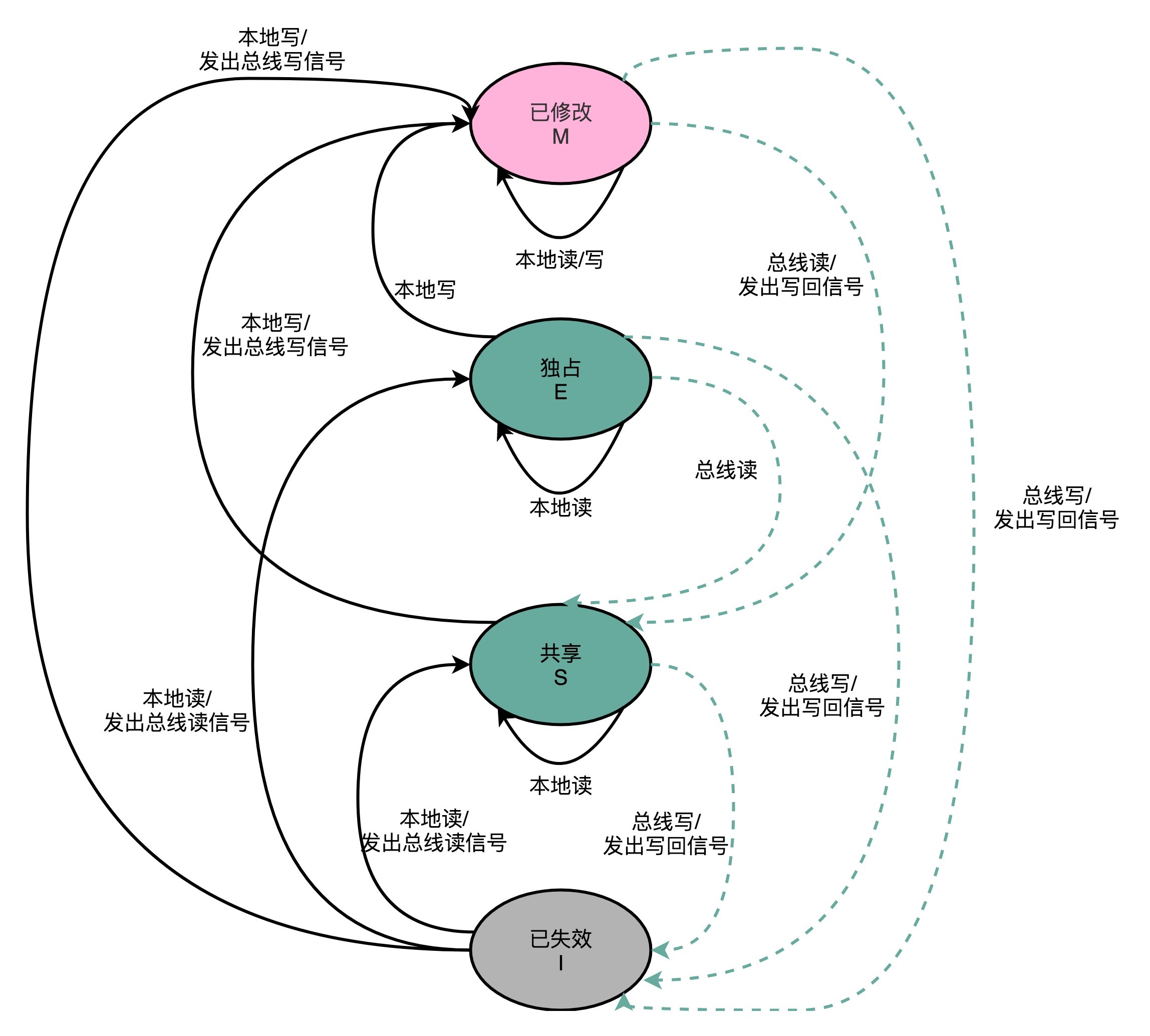
MESI 协议,是一种叫作写失效(Write Invalidate)的协议。在写失效协议里,只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 Cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个“失效”版本的 Cache Block,然后把这个也标记成失效的就好了。
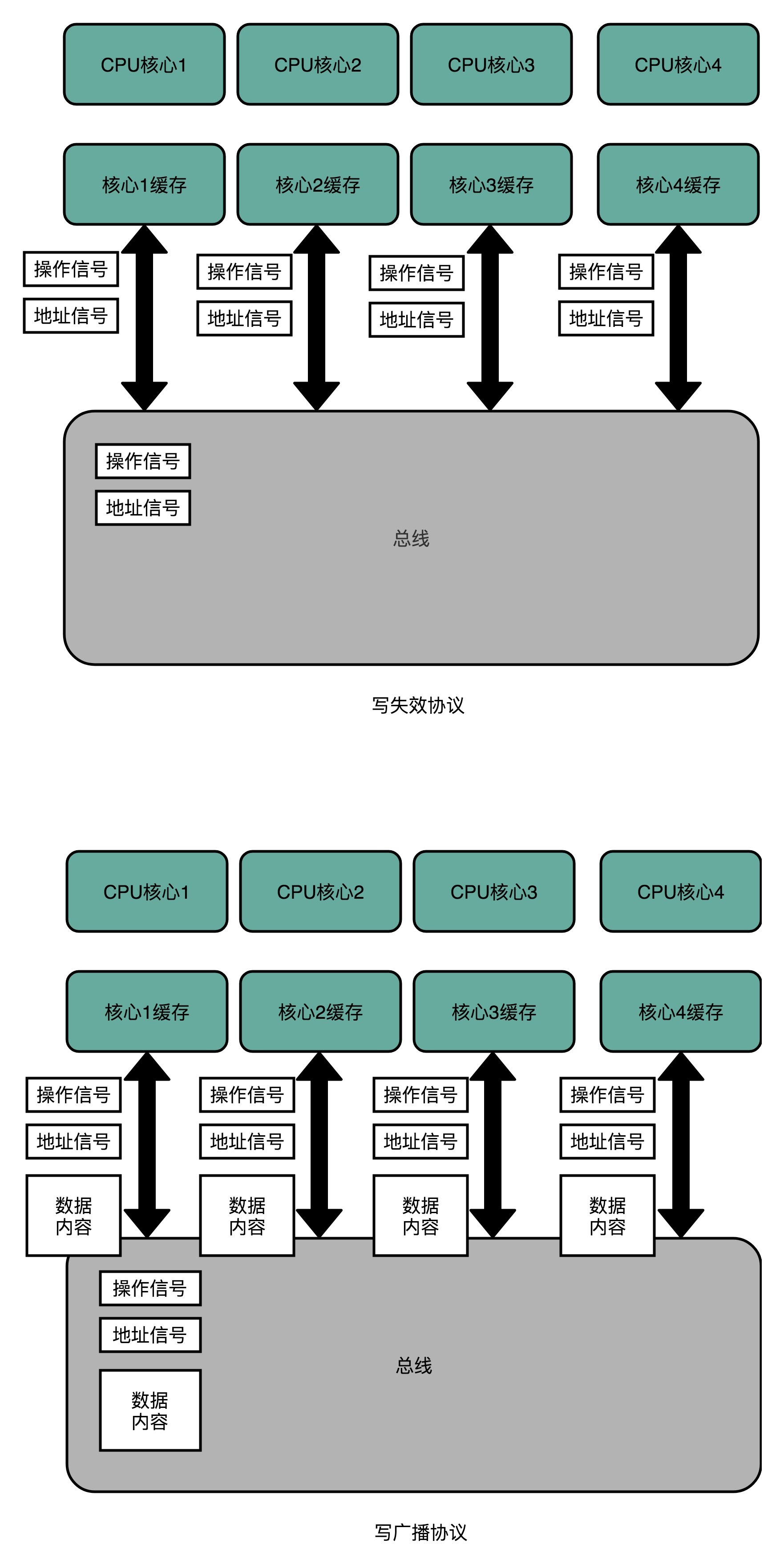
MESI协议的由来呢,来自于我们对 Cache Line 的四个不同的标记,分别是:
M:代表已修改(Modified)
E:代表独占(Exclusive)
S:代表共享(Shared)
I:代表已失效(Invalidated)
我们先来看看“已修改”和“已失效”,这两个状态比较容易理解。所谓的“已修改”,就是我们上一讲所说的“脏”的 Cache Block。Cache Block 里面的内容我们已经更新过了,但是还没有写回到主内存里面。而所谓的“已失效“,自然是这个 Cache Block 里面的数据已经失效了,我们不可以相信这个 Cache Block 里面的数据。
然后,我们再来看“独占”和“共享”这两个状态。这就是 MESI 协议的精华所在了。无论是独占状态还是共享状态,缓存里面的数据都是“干净”的。这个“干净”,自然对应的是前面所说的“脏”的,也就是说,这个时候,Cache Block 里面的数据和主内存里面的数据是一致的。
那么“独占”和“共享”这两个状态的差别在哪里呢?这个差别就在于,在独占状态下,对应的 Cache Line 只加载到了当前 CPU 核所拥有的 Cache 里。其他的 CPU 核,并没有加载对应的数据到自己的 Cache 里。这个时候,如果要向独占的 Cache Block 写入数据,我们可以自由地写入数据,而不需要告知其他 CPU 核。
在独占状态下的数据,如果收到了一个来自于总线的读取对应缓存的请求,它就会变成共享状态。这个共享状态是因为,这个时候,另外一个 CPU 核心,也把对应的 Cache Block,从内存里面加载到了自己的 Cache 里来。
而在共享状态下,因为同样的数据在多个 CPU 核心的 Cache 里都有。所以,当我们想要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他 CPU 核心里面的 Cache,都变成无效的状态,然后再更新当前 Cache 里面的数据。这个广播操作,一般叫作 RFO(Request For Ownership),也就是获取当前对应 Cache Block 数据的所有权。
有没有觉得这个操作有点儿像我们在多线程里面用到的读写锁。在共享状态下,大家都可以并行去读对应的数据。但是如果要写,我们就需要通过一个锁,获取当前写入位置的所有权。
整个 MESI 的状态,可以用一个有限状态机来表示它的状态流转。需要注意的是,对于不同状态触发的事件操作,可能来自于当前 CPU 核心,也可能来自总线里其他 CPU 核心广播出来的信号。我把对应的状态机流转图放在了下面,你可以对照着 Wikipedia 里面 MESI 的内容,仔细研读一下。
Title: 计算机组成原理 - 高速缓存
Author: Jiandong
Date: 2020-11-22
Last Update: 2025-02-23
Blog Link: https://mjd507.github.io/2020/11/22/Computer-Organization-8/
Copyright Declaration: Please refer carefully, most of the content I have not fully mastered.