Linux 性能优化 - CPU 篇
本文参考极客时间付费课程,将众多 CPU 相关的知识柔和成一篇,细节部分没有连贯,仅作为学习记录笔记。
一些工具,比如 sysstat (pidstat、mpstat、vmstat、iostat、…),stress-ng,sysbench,自行参考 man 手册,不在解释说明。
平均负载(load avg)高的三种场景
平均负载(load average)是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
平均负载高,可能有以下三种情况:
- CPU 密集型进程,频繁计算
- io 密集型进程,等待 I/O
- 大量进程,等待 CPU 的调度
CPU 密集型进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29# 模拟 cpu 一个核忙碌场景
stress-ng --cpu 1 --timeout 600
# 通过第二个终端,观察平均负载。-d 参数表示高亮显示变化的区域
watch -d uptime
# 通过第三个终端,观察 CPU 每个核的使用情况
# -P ALL 表示监控所有CPU,5 表示间隔 5 秒后输出一组数据
mpstat -P ALL 5 1
Linux 4.4.0-18362-Microsoft (DESKTOP-QA5VN0F) 02/26/21 _x86_64_ (8 CPU)
18:53:00 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
18:53:05 all 12.62 0.00 0.15 0.00 0.00 0.00 0.00 0.00 0.00 87.23
18:53:05 0 1.40 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 98.20
18:53:05 1 0.60 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.40
18:53:05 2 0.80 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 98.80
18:53:05 3 9.02 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 90.98
18:53:05 4 4.60 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 95.40
18:53:05 5 10.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 89.80
18:53:05 6 28.14 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 71.86
18:53:05 7 46.20 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 53.40
# 通过 `pidstat` 命令,查看哪个进程 CPU 使用率较高。
# 间隔5秒后输出一组数据
pidstat 5 1
18:55:57 UID PID %usr %system %guest %wait %CPU CPU Command
18:56:02 0 1449 100.40 0.00 0.00 0.00 100.40 0 stress-ng-cpuI/O 密集型进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# 模拟 io 场景,--hdd 表示读写临时文件
stress-ng --io 1 -d 1 --timeout 600
# 通过第二个终端,观察平均负载。-d 参数表示高亮显示变化的区域
watch -d uptime
# 通过第三个终端,观察 CPU 每个核的使用情况
# -P ALL 表示监控所有CPU,5 表示间隔 5 秒后输出一组数据
mpstat -P ALL 5 1
21:12:29 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
21:12:32 all 4.21 0.00 17.58 0.00 0.00 0.00 0.00 0.00 0.00 78.22
21:12:32 0 0.33 0.00 9.36 0.00 0.00 0.00 0.00 0.00 0.00 90.30
21:12:32 1 0.33 0.00 5.33 0.00 0.00 0.00 0.00 0.00 0.00 94.33
21:12:32 2 0.67 0.00 12.00 0.00 0.00 0.00 0.00 0.00 0.00 87.33
21:12:32 3 1.66 0.00 5.98 0.00 0.00 0.00 0.00 0.00 0.00 92.36
21:12:32 4 0.66 0.00 13.62 0.00 0.00 0.00 0.00 0.00 0.00 85.71
21:12:32 5 4.67 0.00 16.67 0.00 0.00 0.00 0.00 0.00 0.00 78.67
21:12:32 6 10.00 0.00 34.33 0.00 0.00 0.00 0.00 0.00 0.00 55.67
21:12:32 7 15.33 0.00 43.33 0.00 0.00 0.00 0.00 0.00 0.00 41.33
这里 iowait 为 0,暂不清楚原因。
# 通过 `pidstat` 命令,查看哪个进程 CPU 使用率较高。
# 间隔5秒后输出一组数据
pidstat 5 1
21:12:37 UID PID %usr %system %guest %wait %CPU CPU Command
21:12:40 1000 1536 31.67 68.33 0.00 0.00 100.00 0 stress-ng-io
21:12:40 1000 1537 1.33 47.67 0.00 0.00 49.00 0 stress-ng-hdd大量进程场景
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 模拟 cpu 8 个核工作场景
stress-ng --cpu 8 --timeout 600
# 通过 `pidstat` 命令,查看一下进程情况
pidstat 5 1
21:27:05 UID PID %usr %system %guest %wait %CPU CPU Command
21:27:10 1000 1541 86.67 0.00 0.00 0.00 86.67 0 stress-ng-cpu
21:27:10 1000 1542 87.00 0.00 0.00 0.00 87.00 0 stress-ng-cpu
21:27:10 1000 1543 87.00 0.00 0.00 0.00 87.00 0 stress-ng-cpu
21:27:10 1000 1544 86.50 0.00 0.00 0.00 86.50 0 stress-ng-cpu
21:27:10 1000 1545 87.00 0.00 0.00 0.00 87.00 0 stress-ng-cpu
21:27:10 1000 1546 86.67 0.00 0.00 0.00 86.67 0 stress-ng-cpu
21:27:10 1000 1547 86.33 0.00 0.00 0.00 86.33 0 stress-ng-cpu
上下文切换(context switch)场景分析
利用 sysbench,模拟系统多线程调度的瓶颈
1 | # 使用 vmstat 观察系统空闲时上下文切换次数 |
CPU 使用率过高分析
top 和 ps 是最常用的性能分析工具。
- top 显示系统整体的 CPU 和内存使用情况,默认每 3 秒刷新一次
- ps 则只显示了每个进程的资源使用情况,默认收集进程的整个生命周期
再借助 pidstat 详细了解 cpu 的使用率分布。(%usr 用户态,%sys 内核态,%wait 等待CPU,%guest 运行虚拟机CPU)
再进一步,借助 perf 定位到占用 CPU 较多的代码函数。
CPU 使用率高,但却找不到进程
无论通过 top、pidstat、ps 都找不到 CPU 使用率高的进程,但系统整体 CPU 使用率就是很高。
此时,很可能出现了大量的短进程,也就是在应用内部通过 exec 调用的外面命令,这些命令一般都只运行很短的时间就会结束。
通过 top 命令观察 Tasks 一行,此时一般会存在数个 Running 状态的进程。
perf 工具用在这里也很合适。
1 | # 记录性能事件,等待大约15秒后按 Ctrl+C 退出 |
此外,execsnoop 也是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
软中断导致 CPU 使用率升高
Linux 将中断分为上下两个部分,来解决中断处理程序执行过长和中断丢失的问题。
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
最常见的网卡接收数据包。网卡接收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了。这时,内核就应该调用中断处理程序来响应它。
/proc/softirqs 提供了软中断的运行情况;
/proc/interrupts 提供了硬中断的运行情况。
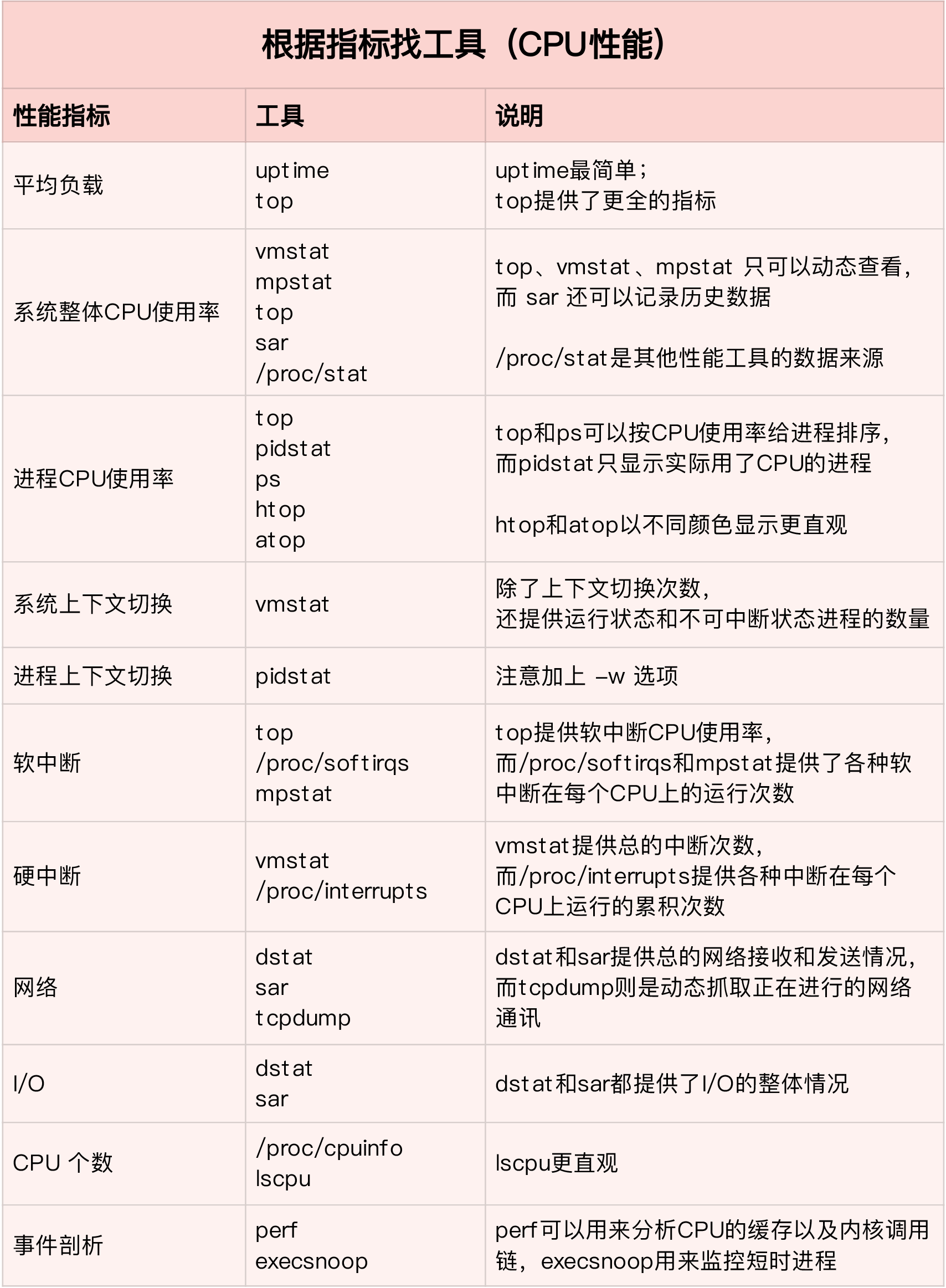
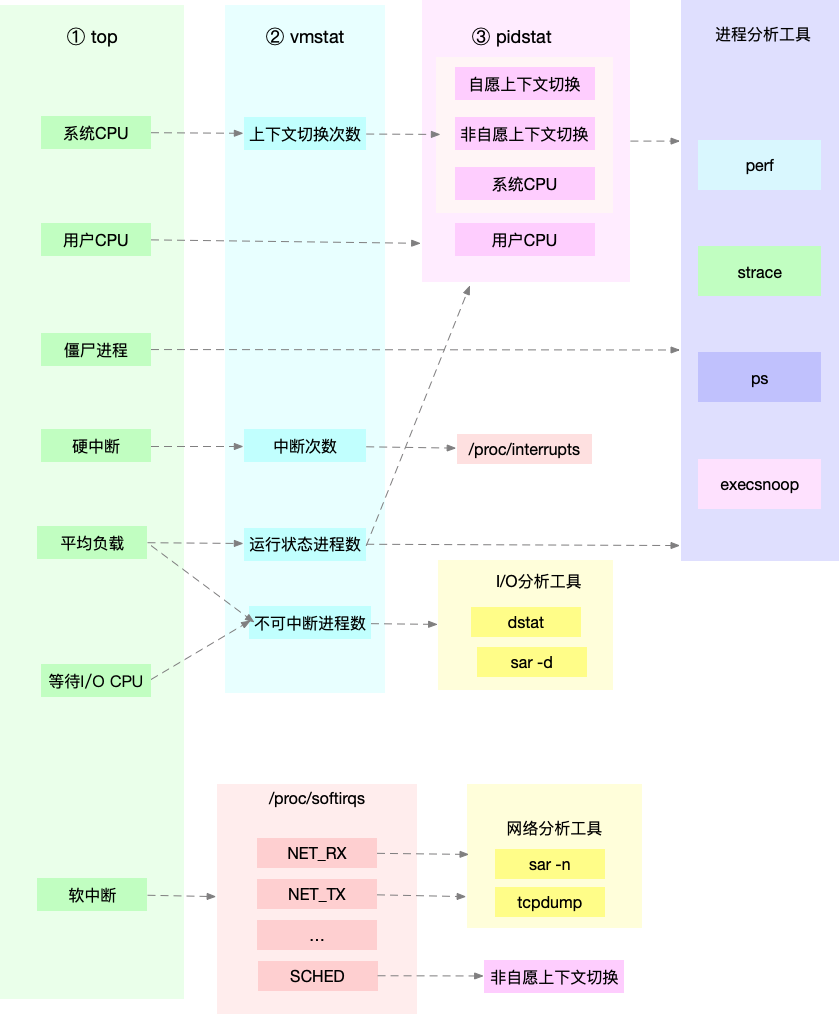
整体分析 CPU 瓶颈思路
Title: Linux 性能优化 - CPU 篇
Author: Jiandong
Date: 2021-02-27
Last Update: 2025-02-23
Blog Link: https://mjd507.github.io/2021/02/27/Linux-Perf-Cpu-1/
Copyright Declaration: Please refer carefully, most of the content I have not fully mastered.